前情摘要:https://assbbs.com/thread-36208.htm
看到NodeSeek分页限制在100页,手贱点进去还把他们网站搞到503崩了。
传统的MySQL分页模式,在offset跳过数据过大的时候,就会变慢。
因此我采用了B+树磁盘存储,把key链表顺序缓存到内存。
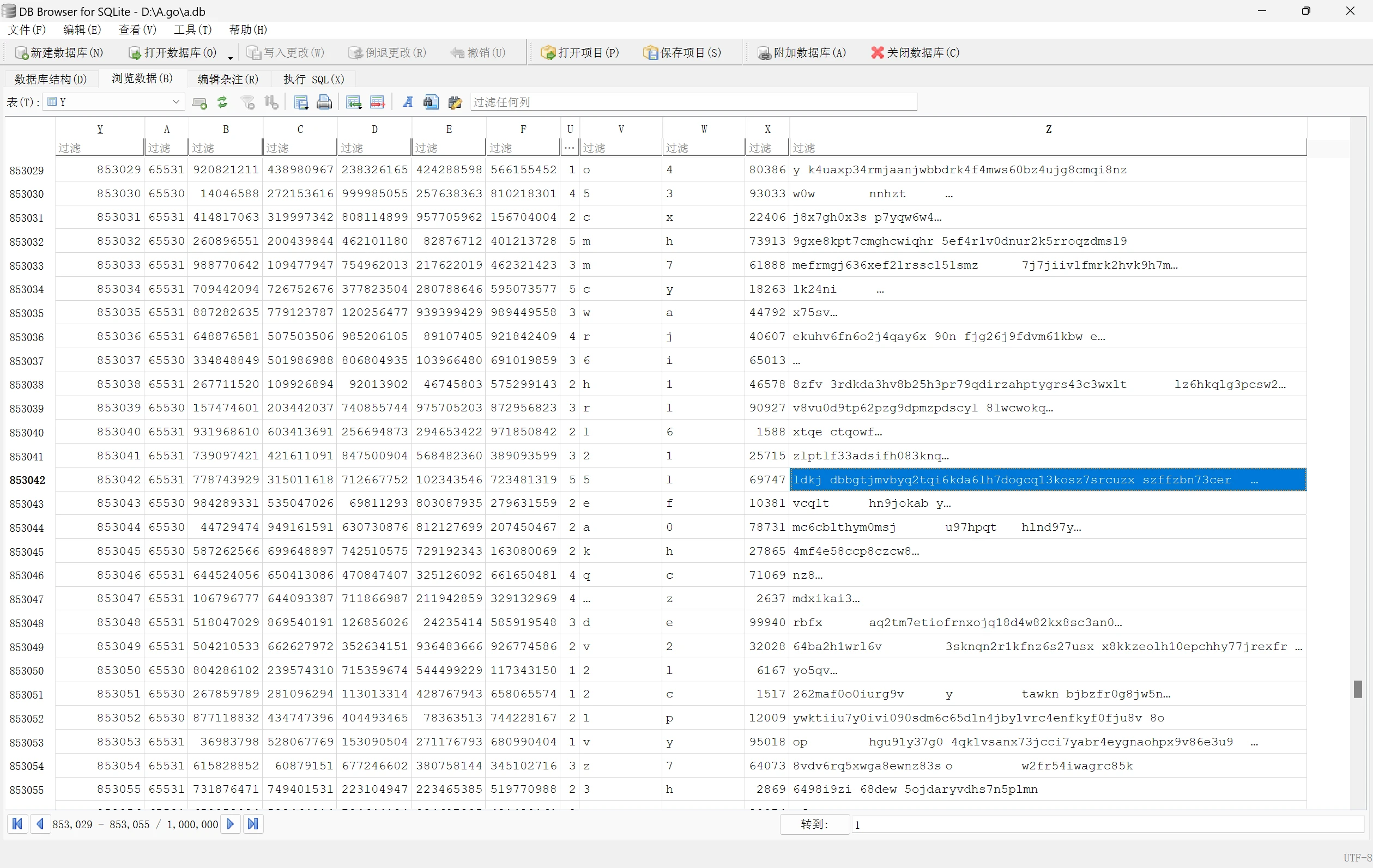
100万条数据测试结果:
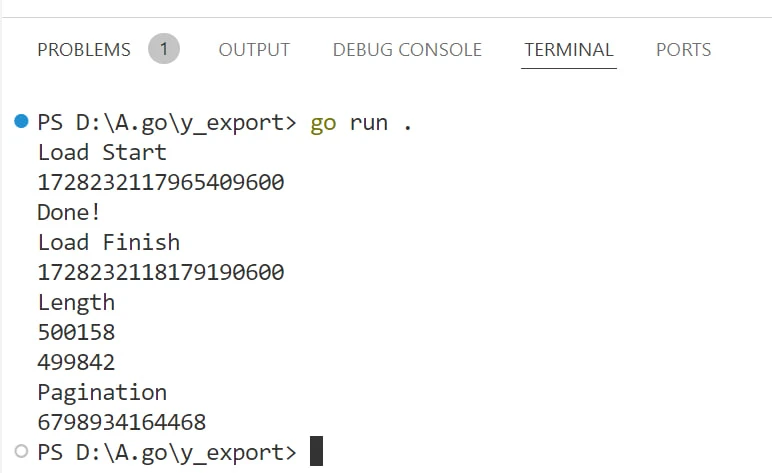
B+树读取链表到内存,用时213ms。
按阅读权限写入两个Map列,数据合计无误。
取第888888条数据,几乎没有任何分页时间。
(不到1ms,理论上1亿数据速度也相差不大)
按此分页key中的数据,从SQLite加载行即可。
试验可行,明天就把数据融合到程序中去。
测试数据样例: